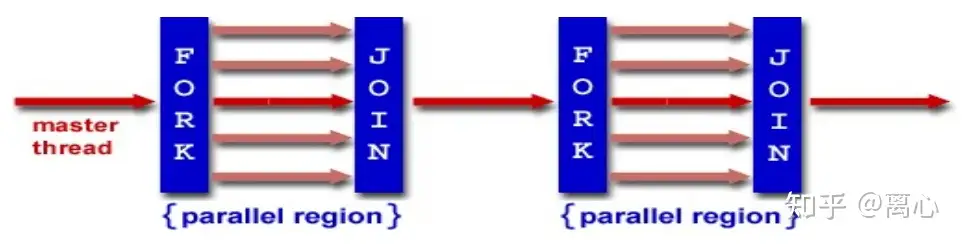
intmain_1(){ int tid, tnum; #pragma omp parallel private(tid, tnum) { tid = omp_get_thread_num(); tnum = omp_get_num_threads(); printf("Hello OpenMP from thread %d in %d CPUs\n", tid, tnum); }
return0; }
L2
omp_get_thread_num
设置使用的线程数
for
对接下来的 for 语句做并行循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#include<iostream> #include<omp.h>
usingnamespace std;
intmain_2(){ int tid, tnum; omp_set_thread_num(10); #pragma omp parallel for for (int i = 0; i < 100; i++) printf("Hello OpenMP from thread %d\n", omp_get_thread_num());
voidStatic_(){ omp_set_num_threads(2); int n, idx, i;
#pragma omp parallel for private(i) schedule(static) for (i = 0; i < 10; i++) { int n = omp_get_num_threads(); int idx = omp_get_thread_num(); printf("Nthreads:%d id:%d out:%d\n", n, idx, i); }
return; }
voidStatic_s(){ omp_set_num_threads(2); int n, idx, i;
#pragma omp parallel for private(i) schedule(static, 4) for (i = 0; i < 10; i++) { int n = omp_get_num_threads(); int idx = omp_get_thread_num(); printf("Nthreads:%d id:%d out:%d\n", n, idx, i); }
return; }
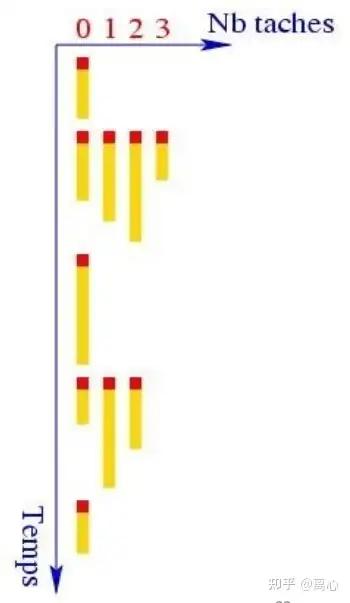
voidDynamic_(){ omp_set_num_threads(2); int n, idx, i;
#pragma omp parallel for private(i) schedule(dynamic) for (i = 0; i < 10; i++) { int n = omp_get_num_threads(); int idx = omp_get_thread_num(); printf("Nthreads:%d id:%d out:%d\n", n, idx, i); }
return; }
voidDynamic_s(){ omp_set_num_threads(2); int n, idx, i;
#pragma omp parallel for private(i) schedule(dynamic, 4) for (i = 0; i < 10; i++) { int n = omp_get_num_threads(); int idx = omp_get_thread_num(); printf("Nthreads:%d id:%d out:%d\n", n, idx, i); }
return; }
voidGuided_(){ omp_set_num_threads(2); int n, idx, i;
#pragma omp parallel for private(i) schedule(guided) for (i = 0; i < 10; i++) { int n = omp_get_num_threads(); int idx = omp_get_thread_num(); printf("Nthreads:%d id:%d out:%d\n", n, idx, i); }
return; }
intmain_4(){ Guided_(); return0; }
L5
critical
说明后续并行代码段是原子的
atomic
说明后续操作是原子的,比 critical 更高效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
#include<iostream> #include<omp.h>
usingnamespace std;
intmain_5(){ int res = 0; #pragma omp parallel for for (int i = 0; i < 1000000; i++) // #pragma omp atomic #pragma omp critical res++;
 wechat
wechat